HTTP의 정의와 동작 방식, GET,POST 방식차이
프로토콜
프로토콜은 컴퓨터 내부에서, 또는 컴퓨터 사이에서 데이터의 교환 방식을 정의하는 규칙 체계입니다. 기기 간 통신은 교환되는 데이터의 형식에 대해 상호 합의를 요구합니다. 이런 형식을 정의하는 규칙의 집합을 프로토콜이라고 합니다.
간단히 예를 들면 '1'과 '2'라는 데이터를 보낼 때도 이진법(컴퓨터는 당연히 이진법)으로 16bit를 사용해서 데이터를 주고 받자라고 미리 약속을 합니다.
그러고 나서 약속한대로 0000 0000 0000 0001 / 0000 0000 0000 0010 를 보내면 이를 받는 쪽에서도 당연히 16bit로 왔다는걸 알고 '1'과 '2'라고 인식하는 것입니다.
HTTP 프로토콜이란?
HTTP(Hypertext Transfer Protocol)는 웹을 개발하는 사람이라면 누구나 다 알아야 하는 통신 프로토콜입니다.
웹에서는 브라우저와 서버 간에 데이터를 주고받기 위한 방식으로 HTTP 프로토콜을 사용하고 있습니다.
HTTP 요청과 응답
웹 뿐만 아니라 server-client 관계에서는 client가 요청(request)하면 서버가 요청을 처리한 후 client에게 응답(response)합니다. 단지 웹에서는 이 요청과 응답을 HTTP 방식으로 요청하고 응답하기로 한 것입니다.
HTTP 프로토콜로 데이터를 주고받기 위해서는 아래와 같이 요청(Request)을 보내고 응답(Response)을 받아야 합니다.

HTTP통신에서의 client는 브라우저(크롬,exploer 등)이 되고
server는 저희가 아는 WAS(톰캣, ZEUS 등)이 되는 것입니다.
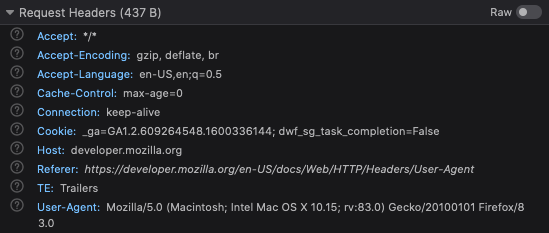
Http Request Message의 구조
크게 3부분으로 구성된다.

- start line(request line) : Http request의 첫 라인으로써, 3 부분으로 구성된다
- HTTP Method: GET, POST 등 action을 정의.
- Request target: request가 전송되는 uri (endpoint)
- HTTP Version
- headers : request에 대한 meta정보를 담고 있으며, key:value 값으로 되어있다.
- Host : 요청이 전송되는 target의 host url: 예를 들어, google.com
- User-Agent : 요청을 보내는 클라이언트의 대한 정보: 사용하는 웹 브라우저와 버전, OS 등
- Accept : 해당 요청이 받을 수 있는 응답(response) 타입.
(조건부 요청을 허용: (accept-, If-), 모든 요청 허용:(/)) - Connection : 해당 요청이 끝난후에 클라이언트와 서버가 계속해서 네트워크 컨넥션을 유지 할것인지 아니면 끊을것인지에 대해 지시하는 부분. (Keep-alive or cancel)
- Content-Type : 해당 요청이 보내는 메세지 body의 타입. 예를 들어, JSON을 보내면 application/json.
- Content-Length :메세지 body의 길이
- empty line: 요청에 대한 meta 정보가 전송되었음을 알린다.
- body:
- 해당 request의 실제 메세지/내용이 들어있다.
- XML 이나 JSON 데이터가 들어갈 수 있다.
- GET은 body가 대부분 없다.
Http Response Message의 구조
기본적인 구조는 request와 비슷하다.

- status line : response의 상태를 간략하게 나타내며, 3부분으로 구성되어 있다
- HTTP version
- status code : 응답 상태를 나타내는 코드
- status text : 응답 상태의 설명 (ex: Not Found)
- headers :
- request의 header와 동일하다
- response에서만 사용되는 header 값이 있다 (예: User-Agent가 없고, Server가 있음).
- empty line
- body : 실제 응답하는 데이터를 나타낸다. status 2XX의 경우, 존재하지 않는 경우가 많다.
response header의 예시:

URL
URL(Uniform Resource Locators)은 개발자가 아니더라도 이미 우리에게 익숙한 용어입니다. 서버에 자원을 요청하기 위해 입력하는 영문 주소죠. 아무래도 숫자로 되어 있는 IP 주소보다는 훨씬 기억하기 쉽기 때문에 사용하는 것 같습니다.
URL 구조는 아래와 같습니다.

이 때 브라우저 주소창에 URL을 입력하면 해당 주소(host)에 맞는 서버컴퓨터로 가게되고
포트(port)를 통해 서버컴퓨터의 특정 WAS로 가게되고 나머지 resource path를 통해 특정 페이지까지 요청이 됩니다.
예를 들면 http://localhost:8080/study/01basic/00hello.jsp
또는 http://192.168.0.76:8080/study/01basic/00hello.jsp를
브라우저에서 입력하면 localhost나 192.168.0.76(현재 내 컴퓨터 내부 ip주소)을 통해 자기 컴퓨터에 가고
8080포트를 통해 내 컴퓨터의 톰캣으로 가게됩니다. (이 때 내 컴퓨터의 톰캣이 켜져있어야 합니다)
그리고 나머지 resource path를 통해 00hello.jsp까지 간다면 톰캣이 해당 요청을 처리해 응답하면
브라우저는 응답을 받아 00hello.jsp의 화면을 보여주게 되는 식입니다.
글 마지막에 이미지를 보면 좀 더 이해하기 쉬울것입니다.
HTTP 요청 메서드
앞에서 살펴본 URL을 이용하면 서버에 특정 데이터를 요청할 수 있습니다. 여기서 요청하는 데이터에 특정 동작을 수행하고 싶으면 어떻게 해야 할까요? 바로 HTTP 요청 메서드(Http Request Methods)를 이용합니다.
일반적으로 HTTP 요청 메서드는 HTTP Verbs라고도 불리우며 아래와 같이 주요 메서드를 갖고 있습니다.
- GET : 존재하는 자원에 대한 요청
- POST : 새로운 자원을 생성
- PUT : 존재하는 자원에 대한 변경
- DELETE : 존재하는 자원에 대한 삭제
이와 같이 데이터에 대한 조회, 생성, 변경, 삭제 동작을 HTTP 요청 메서드로 정의할 수 있습니다.
PUT,DELETE도 post방식으로 가능합니다.
사실 대부분 GET,POST방식만 사용합니다.
HTTP 상태 코드
앞에서 살펴본 URL과 요청 메서드가 클라이언트에서 설정해야 할 정보라면 HTTP 상태 코드(HTTP Status Code)는 서버에서 설정해주는 응답(Response) 정보입니다.
프런트엔드 개발자 입장에서는 더욱이 중요한 이유가 이 상태 코드로 에러 처리를 할 수 있기 때문입니다. 간단한 예시를 들어 아래와 같이 사용자 목록을 받아오는 GET 메서드 요청을 날려보겠습니다.
위 요청을 보내고 나면 서버에서 응답으로 오는 상태 코드가 크게 2개로 나뉩니다. 200(성공)과 404(실패)입니다. 따라서, 이 HTTP 상태 코드로 추가적인 로직을 구현할 수 있죠.
주요 상태 코드는 200번대부터 500번대까지 다양하게 있지만 주요한 상태 코드만 몇 개 살펴보겠습니다.
2xx - 성공
200번대의 상태 코드는 대부분 성공을 의미합니다.
- 200 : GET 요청에 대한 성공
- 204 : No Content. 성공했으나 응답 본문에 데이터가 없음
- 205 : Reset Content. 성공했으나 클라이언트의 화면을 새로 고침하도록 권고
- 206 : Partial Conent. 성공했으나 일부 범위의 데이터만 반환
3xx - 리다이렉션
300번대의 상태 코드는 대부분 클라이언트가 이전 주소로 데이터를 요청하여 서버에서 새 URL로 리다이렉트를 유도하는 경우입니다.
- 301 : Moved Permanently, 요청한 자원이 새 URL에 존재
- 303 : See Other, 요청한 자원이 임시 주소에 존재
- 304 : Not Modified, 요청한 자원이 변경되지 않았으므로 클라이언트에서 캐싱된 자원을 사용하도록 권고. ETag와 같은 정보를 활용하여 변경 여부를 확인
4xx - 클라이언트 에러
400번대 상태 코드는 대부분 클라이언트의 코드가 잘못된 경우입니다. 유효하지 않은 자원을 요청했거나 요청이나 권한이 잘못된 경우 발생합니다. 가장 익숙한 상태 코드는 404 코드입니다. 요청한 자원이 서버에 없다는 의미죠.
- 400 : Bad Request, 잘못된 요청
- 401 : Unauthorized, 권한 없이 요청. Authorization 헤더가 잘못된 경우
- 403 : Forbidden, 서버에서 해당 자원에 대해 접근 금지
- 405 : Method Not Allowed, 허용되지 않은 요청 메서드
- 409 : Conflict, 최신 자원이 아닌데 업데이트하는 경우. ex) 파일 업로드 시 버전 충돌
5xx - 서버 에러
500번대 상태 코드는 서버 쪽에서 오류가 난 경우입니다.
- 501 : Not Implemented, 요청한 동작에 대해 서버가 수행할 수 없는 경우
- 503 : Service Unavailable, 서버가 과부하 또는 유지 보수로 내려간 경우
다시 살펴보는 HTTP 요청과 응답
앞에서 배운 URL, 요청 메서드, 상태 코드를 조합하면 아래와 같은 구조가 나옵니다.

HTTP 메소드 중 GET방식과 POST 방식 차이
get방식이든 post방식이든 둘 다 브라우저가 서버에 요청하는 것입니다.
GET 방식
GET은 요청을 전송할 때 필요한 데이터를 Body에 담지 않고, 쿼리스트링을 통해 전송합니다.
URL의 끝에 ?와 함께 이름과 값으로 쌍을 이루는 요청 파라미터를 쿼리스트링이라고 부릅니다. 만약, 요청 파라미터가 여러 개이면 &로 연결합니다. 쿼리스트링을 사용하게 되면 URL에 조회 조건을 표시하기 때문에 특정 페이지를 링크하거나 북마크할 수 있습니다.
쿼리스트링을 포함한 URL의 샘플은 아래와 같습니다. 여기서 요청 파라미터명은 name1, name2이고, 각각의 파라미터는 value1, value2라는 값으로 서버에 요청을 보내게 됩니다.
www.example-url.com/resources?name1=value1&name2=value2
그리고 GET은 불필요한 요청을 제한하기 위해 요청이 캐시될 수 있습니다. js, css, 이미지 같은 정적 컨텐츠는 데이터양이 크고, 변경될 일이 적어서 반복해서 동일한 요청을 보낼 필요가 없습니다. 정적 컨텐츠를 요청하고 나면 브라우저에서는 요청을 캐시해두고, 동일한 요청이 발생할 때 서버로 요청을 보내지 않고 캐시된 데이터를 사용합니다. 그래서 프론트엔드 개발을 하다보면 정적 컨텐츠가 캐시돼 컨텐츠를 변경해도 내용이 바뀌지 않는 경우가 종종 발생합니다. 이 때는 브라우저의 캐시를 지워주면 다시 컨텐츠를 조회하기 위해 서버로 요청을 보내게 됩니다.
(이게 바로 f12누르고 새로고침 오른쪽 누르는 거)
- GET 요청은 캐시가 가능하다.
- : GET을 통해 서버에 리소스를 요청할 때 웹 캐시가 요청을 가로채 서버로부터 리소스를 다시 다운로드하는 대신 리소스의 복사본을 반환한다. HTTP 헤더에서 cache-control 헤더를 통해 캐시 옵션을 지정할 수 있다.
- GET 요청은 브라우저 히스토리에 남는다.
- GET 요청은 길이 제한이 있다.
- GET 요청은 중요한 정보를 다루면 안된다. (보안)
POST 방식
POST는 리소스를 생성/변경하기 위해 설계되었기 때문에 GET과 달리 전송해야될 데이터를 HTTP 메세지의 Body에 담아서 전송합니다. HTTP 메세지의 Body는 길이의 제한없이 데이터를 전송할 수 있습니다. 그래서 POST 요청은 GET과 달리 대용량 데이터를 전송할 수 있습니다. 이처럼 POST는 데이터가 Body로 전송되고 내용이 눈에 보이지 않아 GET보다 보안적인 면에서 안전하다고 생각할 수 있지만, POST 요청도 크롬 개발자 도구, Fiddler와 같은 툴로 요청 내용을 확인할 수 있기 때문에 민감한 데이터의 경우에는 반드시 암호화해 전송해야 합니다.
그리고 POST로 요청을 보낼 때는 요청 헤더의 Content-Type에 요청 데이터의 타입을 표시해야 합니다.
Content-Type의 종류로는 application/x-www-form-urlencoded, text/plain, multipart/form-data 등이 있다
데이터 타입을 표시하지 않으면 서버는 내용이나 URL에 포함된 리소스의 확장자명 등으로 데이터 타입을 유추합니다. 만약, 알 수 없는 경우에는 application/octet-stream로 요청을 처리합니다.
- POST 요청은 캐시되지 않는다.
- POST 요청은 브라우저 히스토리에 남지 않는다.
- POST 요청은 데이터 길이에 제한이 없다.
GET 과 POST 의 차이점
GET과 POST의 특징만 보아도 차이가 나긴하지만 추가적으로 차이점을 정리해보면 다음과 같다.
- 사용목적 : GET은 서버의 리소스에서 데이터를 요청할 때, POST는 서버의 리소스를 새로 생성하거나 업데이트할 때 사용한다.
- DB로 따지면 GET은 SELECT 에 가깝고, POST는 Create 에 가깝다고 보면 된다.
- 요청에 body 유무 : GET 은 URL 파라미터에 요청하는 데이터를 담아 보내기 때문에 HTTP 메시지에 body가 없다. POST 는 body 에 데이터를 담아 보내기 때문에 당연히 HTTP 메시지에 body가 존재한다.
- 멱등성 (idempotent) : GET 요청은 멱등이며, POST는 멱등이 아니다.
멱등이란?
멱등의 사전적 정의는 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 의미한다.
GET은 리소스를 조회한다는 점에서 여러 번 요청하더라도 응답이 똑같을 것 이다. 반대로 POST는 리소스를 새로 생성하거나 업데이트할 때 사용되기 때문에 멱등이 아니라고 볼 수 있다. (POST 요청이 발생하면 서버가 변경될 수 있다.)